
Poultry Farm Innovation Project
Poultry Farm Innovation Project
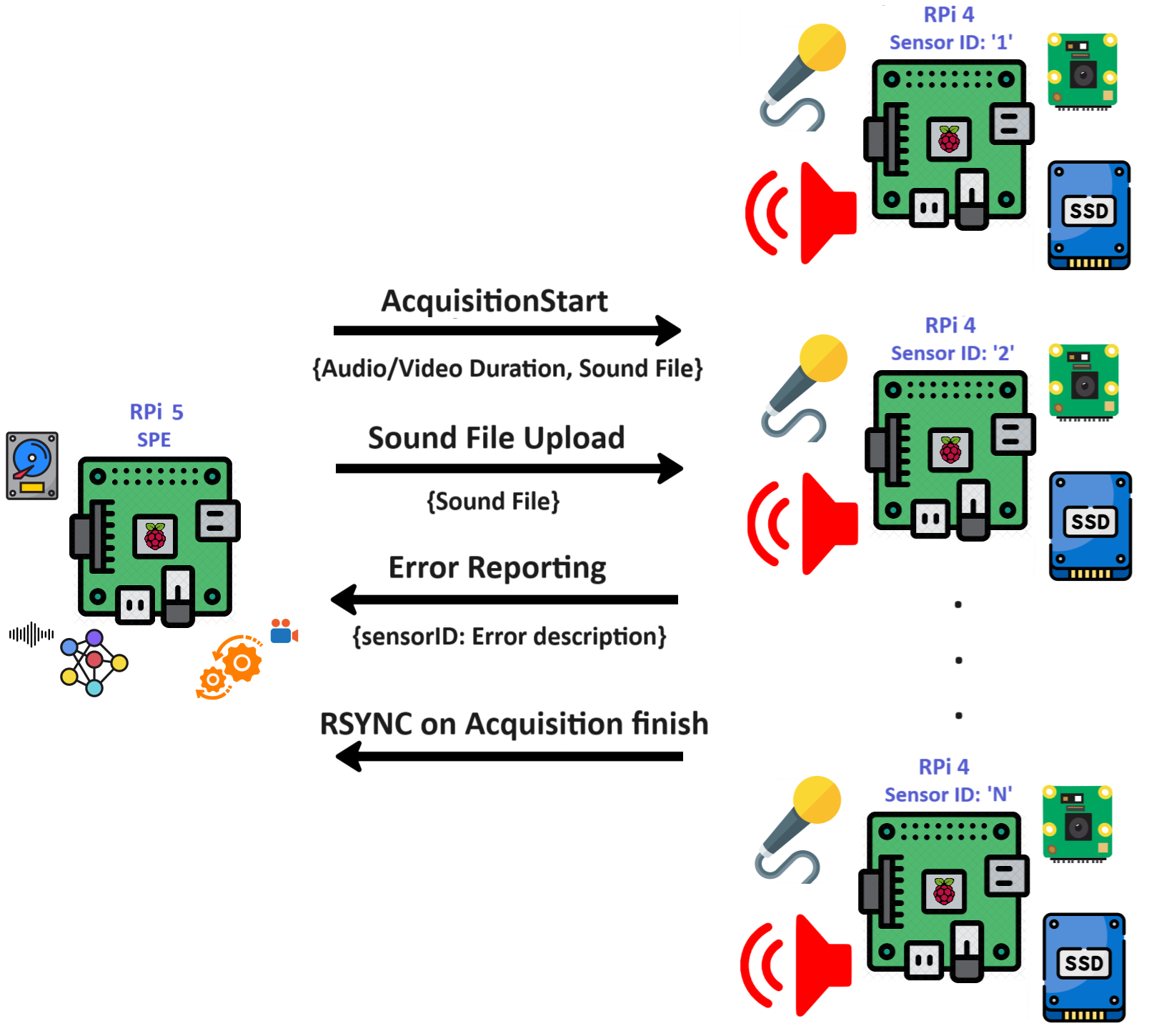
Hardware/Architecture

Audio Anomaly Detection

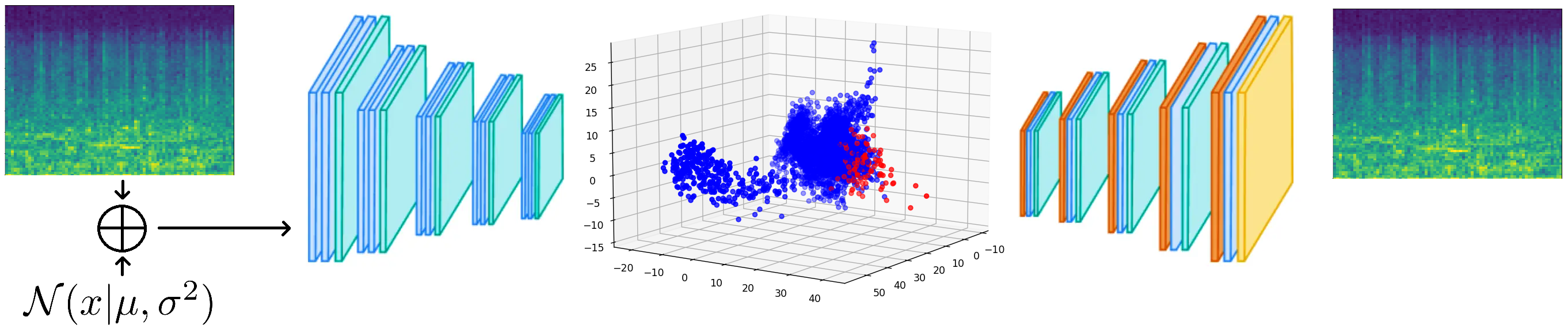
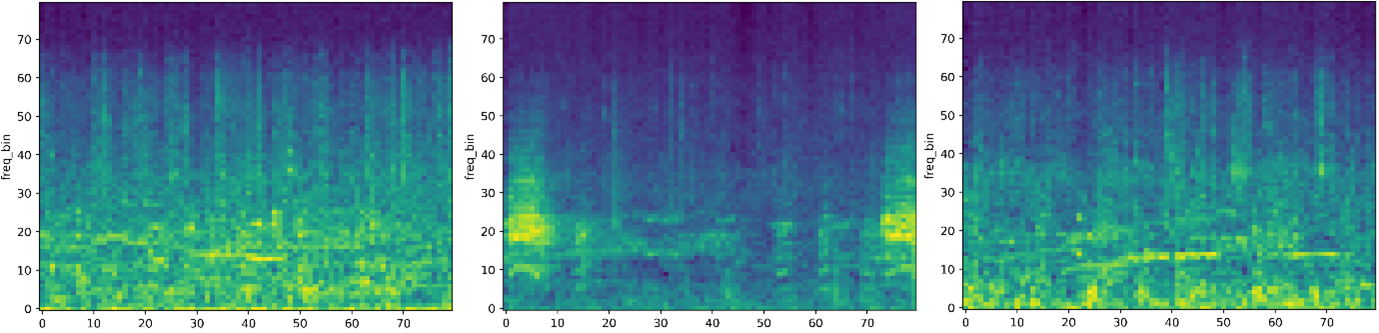
The Mel spectrograms provide a signature of the processed audio that reflects the psychological state of the chicken and thus enable the efficient learning of audio features in chicken clucking or any other sound made by the birds. To learn these audio features, we use unsupervised learning and thus no annotations are required. Specifically, we apply a convolutional denoising autoencoder that learns to reconstruct the Mel spectrograms from their noisy versions.

By learning to restore the true values of the spectrograms, the model learns the features of the problem domain and thus becomes capable of identifying the peculiarities of the data. In other words, the model learns the manifold of the data and distills the low-level audio characteristics that comprise the data. To infer the psychological state of the flock we observe the manifold location where unseen audio samples are mapped on. Since different positions on the manifold reflect different acoustic characteristics, the psychological state of the chicken that causes certain vocal characteristics can be inferred in terms of the mapping of the audio features.
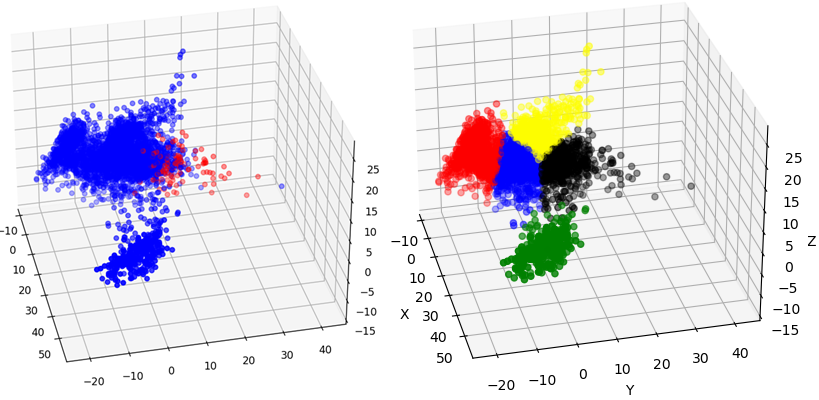
We use PCA to reduce the dimensionality of the audio embeddings to a 3-D space to link the audio semantics of the data points with their distribution in space. Interestingly, the data points are distributed in the 3-D latent space in a way that points with similar semantics are feature-mapped close to each other. For example, most of the audio data points that contain very soft clucking are mapped close to each other at a certain region of the latent space. Likewise, most of the audio data points that contain the clucking of rather stressed chicken are mapped close to each other at a certain region of the feature space. Most importantly, most of the anomalous points (data points with the highest reconstruction error) contain sounds of panicked birds that make distinct sounds of despair.We further cluster the 3-D embeddings with the k-means algorithm into 5 regions. The choice of using 5 regions lies with the way the embeddings are spread onto the feature space. The left figure below shows the 3-D feature space and the data points with the highest reconstruction error are displayed in red color. The right figure below shows the 5 clusters computed with k-means with each cluster shown in a different color. Each cluster computed by the k-means contains semantically different sounds: the points in the red cluster represent low-intensity sounds (flock resting and being very calm), points in the blue cluster represent normal soft clucking, yellow points calm clucking and ambient noises (like food-delivery-machinery), black points represent flock noises ranging from clucking of medium intensity to extremely loud flock sounds (panic sounds) and green points represent very soft clucking and ambient noise (mainly fans blowing air in the farm to cool down the flock). Most importantly, we observe that the anomalous points (the ones with the highest reconstruction loss are located at the extremities of the black cluster (medium to extreme noises).
Motion Detection
Integrating Audio, Video and Sensory data to infer analytics
Next Steps
Project Contributors
Cyens Center of Excellence
1 Plateia Dimarchou Lellou,
Nicosia 1016, Cyprus
Algolysis Ltd
Archiepiskopou Makariou III 200, Lakatamia 2311, Nicosia, Cyprus